Product
AI에 넣기 전에 개인정보부터 가려야 합니다
상담 기록, 고객 메모, 내부 문서를 AI에 넣기 전에 이름, 주소, 전화번호, 이메일, 식별번호를 먼저 마스킹해야 하는 이유와 Schift PII Beta의 방향을 정리했습니다.
AI를 업무에 붙이기 시작하면 가장 먼저 부딪히는 문제는 모델 성능이 아닙니다.
문서를 넣을 수 있느냐입니다.
상담 기록을 요약하고 싶습니다. 콜센터 로그를 분류하고 싶습니다. 병원 메모나 법률 상담 내용을 정리하고 싶습니다. 고객 문의를 모아서 반복되는 문제를 찾고 싶습니다.
그런데 실제 업무 문서는 깔끔한 샘플 데이터가 아닙니다.
이름, 전화번호, 주소, 이메일, 주민등록번호처럼 그대로 외부 도구에 넣기 어려운 정보가 문장 안에 섞여 있습니다.
그래서 질문은 이렇게 바뀝니다.
AI로 무엇을 할 수 있나?
보다 먼저,
AI에 넣기 전에 무엇을 지워야 하나?

현실의 문서는 필드가 아니라 문장입니다
개인정보 마스킹은 겉으로 보면 쉬워 보입니다.
전화번호는 숫자 패턴으로 찾고, 이메일은 @가 들어간 문자열을 찾으면 될 것 같습니다. 하지만 실제 업무 문서는 그렇게 단순하지 않습니다.
예를 들어 이런 문장이 있습니다.
의뢰인 김민수(주민등록번호 850205-1234567)는 서울 강남구 테헤란로 521 위워크빌딩 12층에 거주합니다.휴대폰은 010-1234-5678이고, 이메일은 [email protected]입니다.여기에는 여러 종류의 개인정보가 동시에 들어 있습니다.
| 문장 안의 정보 | 마스킹 후 |
|---|---|
| 김민수 | [이름] |
| 850205-1234567 | [식별번호] |
| 서울 강남구 테헤란로 521 위워크빌딩 12층 | [주소] |
| 010-1234-5678 | [전화번호] |
| [email protected] | [이메일] |
출력은 이렇게 바뀌어야 합니다.
의뢰인 [이름](주민등록번호 [식별번호])는 [주소]에 거주합니다.휴대폰은 [전화번호]이고, 이메일은 [이메일]입니다.중요한 점은 개인정보가 정리된 CSV 필드에 들어 있는 것이 아니라, 한국어 문장 안에 자연스럽게 붙어 있다는 것입니다.
처럼 이메일 바로 뒤에 한국어 어미가 붙을 수 있고,
010-1234-5678이고
처럼 전화번호 뒤에 조사와 쉼표가 이어질 수 있습니다.
주소는 더 어렵습니다. 도로명, 건물명, 층수, 동호수, 지번 주소가 섞입니다. 사람 이름은 문맥에 따라 일반 단어와 구분하기 어렵습니다.
이것이 한국어 PII 마스킹을 단순한 정규식 모음으로 끝낼 수 없는 이유입니다.

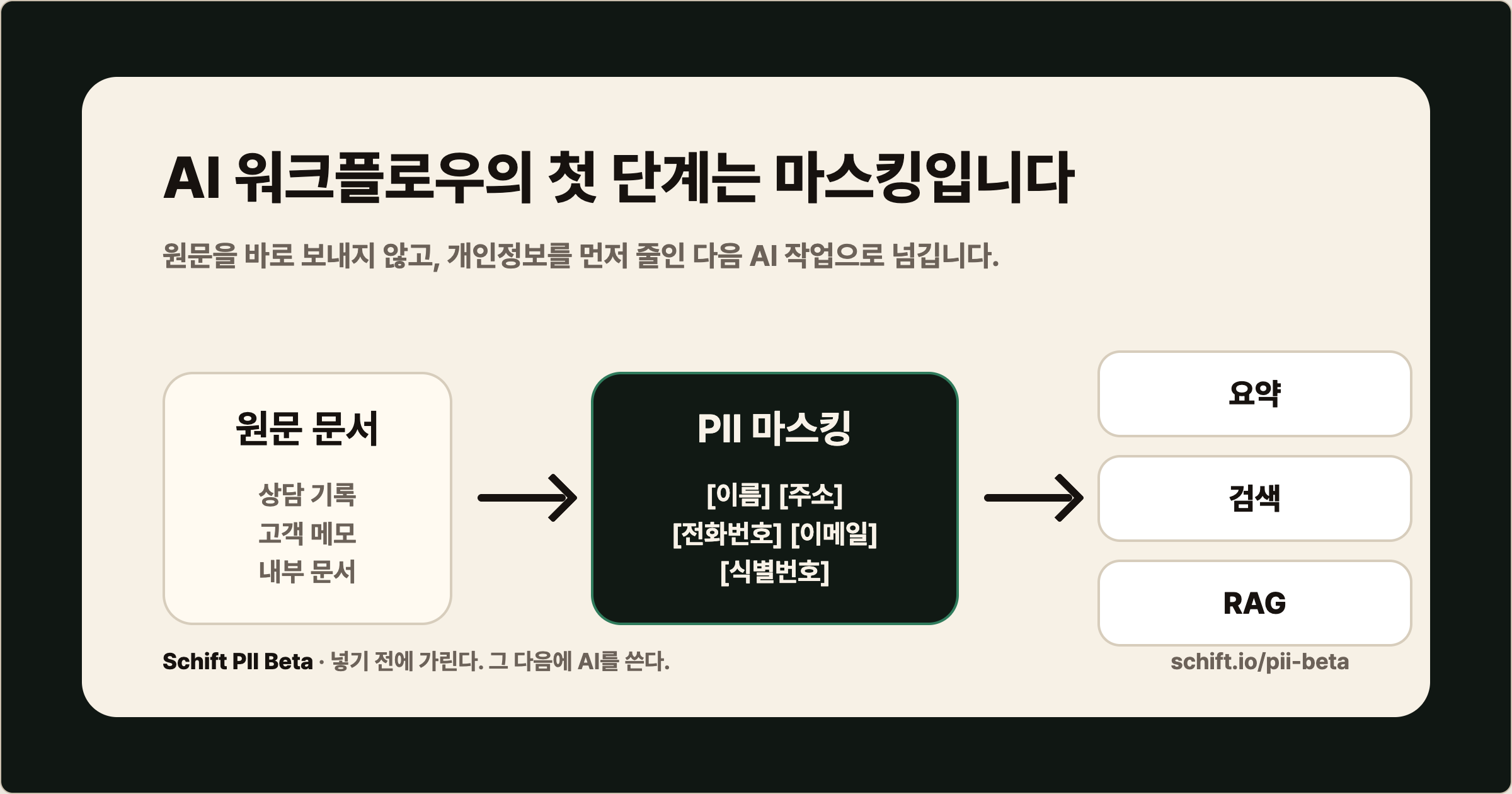
AI 워크플로우에서는 순서가 중요합니다
많은 팀이 AI 도입을 이야기할 때 모델, 프롬프트, RAG, 에이전트부터 봅니다.
하지만 운영 데이터가 들어가는 순간 순서는 달라집니다.
- 원문을 받는다.
- 개인정보를 찾는다.
- 위험한 정보를 마스킹한다.
- 마스킹된 텍스트만 요약, 분류, 검색, RAG, 에이전트에 넘긴다.
이 순서가 뒤집히면 늦습니다.
먼저 embedding을 만들고 나중에 마스킹하면, 원문 개인정보는 이미 embedding input, chunk store, 로그, retry payload, 평가 fixture 어딘가를 지나갔을 수 있습니다.
먼저 LLM에 보내고 나중에 결과만 지우면, 원문은 이미 외부 모델 요청 안에 들어간 뒤입니다.
그래서 Schift의 기준은 단순합니다.
AI에 넣기 전에 먼저 가립니다.
Schift PII Beta는 무엇을 하려고 하나
Schift PII Beta는 한국어 텍스트 안의 개인정보를 찾아 사람이 읽을 수 있는 토큰으로 바꿉니다.
목표는 “완벽한 보안 제품”이라는 큰 말을 하는 것이 아닙니다. 개인정보 탐지는 언제나 오탐과 누락 가능성이 있습니다. 특히 한국어 이름, 주소, 조직명, 숫자 식별자는 문맥에 따라 애매한 경우가 많습니다.
지금의 목표는 더 실용적입니다.
상담 기록이나 내부 문서를 AI에 넣기 전에, 명백한 개인정보 노출 위험을 먼저 줄이는 것.
이런 상황에서 바로 쓸 수 있습니다.
| 사용 상황 | 왜 필요한가 |
|---|---|
| 고객 상담 기록 요약 | 고객 이름, 연락처, 주소가 문장 안에 섞여 있습니다. |
| 콜센터 로그 분석 | 반복 문의를 찾기 전에 전화번호와 이메일을 제거해야 합니다. |
| 법률 상담 문서 검토 | 의뢰인 정보, 주소, 식별번호가 자주 등장합니다. |
| 병원/헬스케어 메모 정리 | 환자 식별 정보와 연락처가 섞일 수 있습니다. |
| 교육/입시 상담 기록 정리 | 학생, 보호자, 학교, 연락처가 함께 등장합니다. |
| 외부 협업용 샘플 문서 공유 | 실제 문서 구조는 유지하되 민감한 값은 가려야 합니다. |
”마스킹”은 삭제와 다릅니다
개인정보를 모두 삭제하면 문서의 의미가 깨질 수 있습니다.
예를 들어 상담 기록에서 주소 전체를 지워버리면 지역 이슈를 알 수 없고, 전화번호를 지워버리면 연락처가 있었다는 사실도 사라집니다.
그래서 Schift는 값을 빈칸으로 없애는 대신, 정보의 종류를 남깁니다.
김민수는 [이름]이 됩니다.
010-1234-5678은 [전화번호]가 됩니다.
[email protected]은 [이메일]이 됩니다.
이렇게 하면 원문 값은 노출하지 않으면서도 문서의 구조와 의미를 유지할 수 있습니다. 이후 요약, 분류, 검색, 담당자 라우팅 같은 작업도 더 자연스럽게 이어집니다.
블로그보다 스레드에 어울리는 핵심 메시지
이 글을 짧게 쪼개면 스레드는 이런 흐름이 됩니다.
- AI에 문서를 넣으려는 순간, 제일 먼저 걸리는 문제는 개인정보다.
- 현실의 상담 기록은 정리된 필드가 아니라 한국어 문장이다.
- 이름, 주소, 전화번호, 이메일, 식별번호가 한 문장 안에 같이 나온다.
- AI 워크플로우에서는 “나중에 지우기”가 아니라 “넣기 전에 가리기”가 맞다.
- Schift PII Beta는 한국어 문장 안의 개인정보를 찾아
[이름],[주소],[전화번호],[이메일]처럼 바꾼다. - 목표는 거창한 보안 선언이 아니라, 문서를 AI에 넣기 전 명백한 노출 위험을 줄이는 것이다.
- 공개 데모에서 직접 테스트할 수 있다.
이미지로 만들면 좋은 컷
스레드나 블로그 카드용 이미지는 복잡한 일러스트보다, 실제 문제가 한눈에 보이는 제품형 이미지가 좋습니다.
1. Before / After 문서 카드
왼쪽에는 원문 상담 기록을 보여주고, 오른쪽에는 마스킹된 결과를 보여줍니다.
핵심 문구:
Before AI, mask the PII.한국어 버전:
AI에 넣기 전, 개인정보부터 가리세요.2. AI 입력 파이프라인
원문 문서가 바로 AI로 들어가는 그림이 아니라,
문서 → PII 마스킹 → 요약 / 검색 / RAG / 에이전트흐름으로 보여주는 이미지가 좋습니다.
핵심은 Schift가 “AI 결과물”이 아니라 “AI에 넣기 전 단계”라는 점입니다.
3. 한국어 문장 속 개인정보
문장 하나를 크게 보여주고, 안에 있는 이름, 주소, 전화번호, 이메일에 얇은 하이라이트를 넣습니다.
이미지는 제품 문제를 바로 설명해야 합니다.
개인정보는 필드가 아니라 문장 안에 있습니다.4. 팀 공유 전 체크
슬랙, 노션, 문서 공유 화면처럼 보이는 장면에서 원문이 아니라 마스킹된 텍스트가 공유되는 구성을 잡습니다.
핵심 문구:
공유하기 전 한 번 더 줄이는 노출 위험5. Beta 고지 카드
데모를 과장하지 않기 위해 Beta 메시지도 따로 카드로 빼는 것이 좋습니다.
Beta: 실제 민감정보는 넣지 말고 테스트 문장으로 확인하세요.이 문구는 신뢰를 만듭니다. 개인정보 제품은 과장보다 경계가 더 중요합니다.
지금 테스트해볼 수 있습니다
Schift PII Beta는 지금 공개 데모로 열려 있습니다.
테스트용 한국어 문장을 붙여넣고, 어떤 정보가 잡히는지 확인해보세요.
이미 더 기술적인 벤치마크와 비교 범위를 보고 싶다면, 별도 기술 글도 있습니다.
한국어 Legal RAG에서 PII를 먼저 지우는 이유
운영 데이터, 상담 로그, 문서 샘플을 AI에 넣는 팀이라면 이제 질문은 하나입니다.
이 문서를 AI에 넣기 전에, 무엇을 먼저 가려야 하나?
RAG Lab 구독
schift 만들면서 직접 굴린 RAG 실험 일지. 매주 새 실험이 올라옵니다.